ACAT2022@Bari
A distributed infrastructure for interactive analysis
Our experience at INFN
Daniele Spiga(1), Diego Ciangottini(1), Mirco Tracolli(1), Piergiulio Lenzi(2), Tommaso Tedeschi(1), Federica Fanzago (3), Massimo Sgaravatto (3), Massimo Biasotto (4), Vincenzo Eduardo Padulano(5), Enrico Guiraud(5), Enric Tejedor Saavedra(5)
INFN Sezione Perugia (1), INFN Sezione Firenze (2), INFN Sezione Padova(3), INFN Sezione Legnaro (4), CERN (5)
for the CMS collaboration
Motivations
The challenges expected for the HL-LHC era, both in terms of storage and computing resources, provide LHC experiments with a strong motivation for evaluating ways of re-thinking their computing models at many levels. In fact a big chunk of the R&D efforts of the CMS experiment have been focused on optimizing the computing and storage resource utilization for the data analysis, and Run3 could provide a perfect benchmark to make studies on new solutions in a realistic scenario.
The work that will be shown is focused on the integration and validation phase of an interactive environment for data analysis with the peculiarity of providing a seamless scaling over grid resources at Italian T2s, and possibly opportunistic providers such as HPC.

Objectives
- * Declarative analysis description, rather than requiring a black belt in code optimization
- * Interactivity and user-friendly/standard UI’s
- * Reducing complexity and maintenance of multiple and slightly overlapping solutions
- * Adopting modern and more efficient analysis frameworks
Implementation pillars
A single HUB for the data analysis
Users should interact with a single entrypoint where they authenticate through the CMS IAM.

Bring in user environment seamlessly
Users can define their container images with all their dependencies and then use them both locally and over all the distributed resources.

Scale seamlessly
New analysis framworks, thanks to their integration with DASK, allows for distributing the very same code you tested locally on different distributed job queues with a single line configuration.
We tried, in other words, to answer the question:"Can we leverage the HTCondor experience we have built for the GRID and build something integrated with Dask? That will provide us with an infrastructure that we know how to manage and extend, but at the same time able to cope with new analysis paradigm!"
A first testbed at INFN
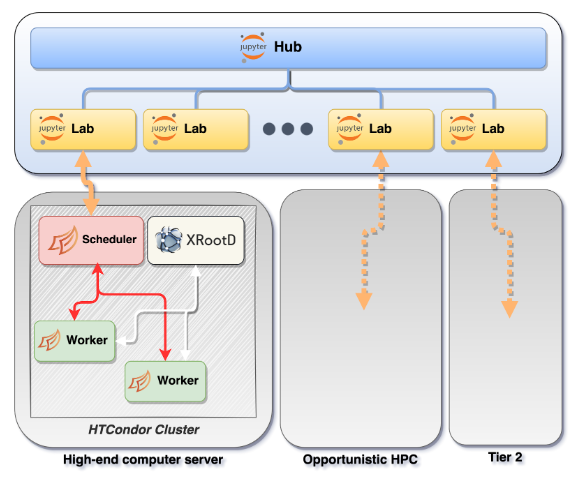
A cluster of resources hosted at CNAF (INFN-Cloud) provide the seed for central services (JupyterHUB, user JupyterLabs, HTCondor scheduling daemons) Additional resources from italian CMS Tier2 are accessible thanks to the on-demand registration of HTCondor worker nodes on the analysis facility pool.
So we came up with a testbed setup to provide a playground for the design of a future analysis infrastructure Leveraging state of the art software toolsets Develop locally than scale out and make use of already-available/spare resources
Integrating new and, maybe, opportunistic resources need a bare minimum set of requirements described on the dedicated documentation. The experience so far indicates an average "time to be ready" from scratch of O(30min).

Evaluating performances
User will login via web and directed to a personal notebook area with a minimum amount of resource for local exploration of the data. Afterwards more resources are made available via a JupyterLab WebUI plugin where user can choose the container image to use and the size of the cluster to be created on-demand. Everything else will happen under the hood, allowing the code to be executed remotely on available resources with almost zero-configuration required.
First benchmarks performed on real CMS analysis
The analysis used as a first benchmark is: VBS SSWW with a light lepton and an hadronic tau in final state: data to be processed for 2017 UL SM analysis: ca. 2TB (Data + MC) It has been ported from legacy approach (nanoAOD-tools/plain PyROOT-based) to RDataFrame. The comparison tests are performed on the same nodes of the cluster with the very same HTCondor infrastructure, trying to keep the benchmark the most fair as possible.
The first round of preliminary measurements are already pointing to an encouraging improvements that comes with little to no tuning needed on the RDataFrame code side.
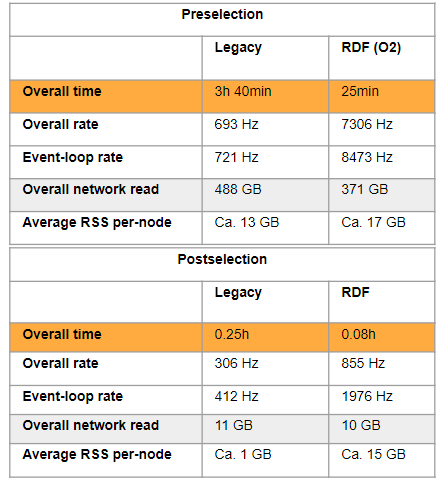
Results of the performance comparison for a VBS analysis implemented on a legacy code framework w.r.t. the RDataFrame implementation. Preselection part refers to the data reduction phase, while at the post selection stage all the actual analysis and statistical studies are performed.
We are working on expanding this tests over multiple use cases (different analysis, different frameworks) to collect some experience and to start a community-driven development path.
At the moment the Data management integration is the current high priority task in our list. The activity included in this topic span from allowing user to import their inputs into the infrastructure via a RUCIO JupyterLab plugin, to the validation of a POSIX accessible shared area for users to distribute configurations to the remote worker nodes.